Large Language Models: Transforming Industries and Reshaping AI Applications
Explore the transformative power of Large Language Models (LLMs) in AI applications. Uncover their impact on industries, ethical considerations, and market projections. Understand how LLMs, based on deep learning techniques, can generate human-like text and reshape various sectors. Read more.

What are Large Language Models?
Large Language Models (LLMs) are artificial intelligence (AI) algorithms rooted in machine learning, particularly leveraging deep learning techniques and massive datasets to understand, generate human-like text, and predict new content. Applying machine learning methodologies allows these models to process and interpret language data efficiently.
LLMs, like ChatGPT/GPT-4, Mistral, etc., are based on the transformer model architecture, enabling them to understand and recognize relationships within the data and perform various natural language processing tasks. Once trained, large language models can also be used for practical purposes such as answering questions, generating new text, summarizing text, or performing sentiment analysis.
LLMs have evolved alongside deep learning models and have become critical to generative AI. The evolution began in the early twentieth century, but large language models emerged significantly after the introduction of neural networks. The Transformer architecture, introduced in 2017, was particularly instrumental. Over time, language models have continued to grow to enhance their performance, using massive amounts of text data and large datasets.
There are different types of LLMs, including zero-shot models. These models are large, generalized, and trained on a generic corpus of data. They can provide accurate results without additional training, making them highly versatile and efficient in generating human language text. Zero-shot models leverage deep learning techniques and massive datasets to understand and generate text and are used in a wide range of natural language processing tasks.
LLMs find applications in various fields, including search engines, natural language processing, healthcare, robotics, and code generation. They can work with multiple languages and possess knowledge of various topics, enabling them to produce text in different styles. They are also used in information retrieval, sentiment analysis, and text generation.
The evolution has been marked by significant models like the Generative Pre-trained Transformer (GPT) series, demonstrating the power of scaling up and generative capabilities. For instance, GPT-3 reshaped perceptions of what LLMs can achieve, expanding possibilities across numerous domains. Other examples include GPT-4, LLaMA, Mistral, the Gemini series, etc.
Large language models have emerged as a transformative technology in artificial intelligence, unlocking new capabilities in generating human-like text and powering innovations across industries. However, as with any rapidly evolving technology, LLMs also pose complex challenges around ethics, privacy, security, bias, and more that must be carefully considered.
How do the Large Language Models work?
Large Language Models (LLMs), a type of generative AI algorithm, leverage deep learning techniques and massive datasets to understand natural language, generate human-like text, and predict new content. They are a subset of generative AI specifically designed to create text-based content.
Massive datasets play a crucial role in the training and functioning of LLMs. These datasets, often consisting of trillions of words, are derived from various sources like books, web pages, and open datasets. The training process involves feeding these vast amounts of data to the model to identify patterns and establish connections between words. The more data used, the better the content generation capability.
The transformer model architecture, a key component, enables them to understand and recognize relationships within the data. This understanding is then used to assign a weight to a given item (token) to determine its relationship with other tokens.
LLMs are trained on large datasets, which helps them develop a rich understanding of the language's syntax, semantics, and context. This pre-training process is crucial for high-performing models, and the quality and quantity of the collected training data significantly impact the model's effectiveness. This training process is a cornerstone of machine learning models, where the model iteratively learns and improves its language understanding from the data. Once trained, language models can generate responses to prompts, which could be answers to questions, newly developed text, summarized text, or sentiment analysis reports.
Underpinning the Architecture of LLMs
The Transformer architecture is pivotal in developing Large Language Models. This architecture's success stems from its ability to utilize machine learning techniques to process and interpret language efficiently, setting a new standard in the field. It is characterized by an encoder-decoder structure, which processes input data and generates output sequentially. The self-attention mechanism within Transformers allows the model to understand the context and weigh the importance of different parts of the input data.
Transformers also have high parallelizability since each word is processed independently in the self-attention layers before aggregating information. This makes transformer models easy to scale up by using multiple GPUs/TPUs to simultaneously process different parts of the input. These advantages have made transformers deeper and larger, leading to significant gains in model performance as measured by metrics like perplexity.
Other Architectures
In addition to the Transformer architecture, other architectures have been used for LLMs:
- Sequence-to-sequence models: These models map input sequences to output sequences and are often used for tasks like machine translation. They can struggle with longer sequences due to their fixed-length context window.
- Recursive neural networks: These models process data with a tree-like structure, which can be useful for capturing hierarchical information in language.
- Convolutional neural networks (CNNs): While more commonly associated with image processing, CNNs can also be used for text by treating sequences of words as one-dimensional images.
The Transformer architecture has been a game-changer for LLMs due to its self-attention mechanism and scalability. While other architectures like sequence-to-sequence, recursive neural networks, and CNNs have contributed to the field, Transformers remain the most influential.
What are the types of Large Language Models?
Large language model types can be categorized based on training objectives, modality, and language breadth.

By Training Objective
- Autoregressive models: Generate text by predicting the next word in a sequence given the previous words (e.g., GPT series).
- Encoder-decoder models: Encode an input sequence (e.g., text) and decode it into an output sequence (e.g., text summary or translated text) (e.g., T5 and BART).
- Bidirectional Encoder Representations from Transformers (BERT): This Transformer encoder model reads input text in both directions, providing a deep contextual understanding of words and their relationships.
- Unlike autoregressive or encoder-decoder models, BERT doesn't directly generate text but produces contextual embeddings for downstream tasks like question answering, sentiment analysis, and named entity recognition.
- Zero-shot and Few-shot models: Zero-shot relies fully on prior knowledge, while few-shot allows slight adaptation using a few examples. Few-shot prompting tends to provide better accuracy compared to zero-shot, at the cost of requiring a small number of labeled examples.
- Fine-tuning generally refers to adapting a pre-trained model to a new task or domain, while domain-specific models are often trained from scratch on domain-specific data.
- Fine-tuned and domain-specific models are language models specifically trained on task-related or domain-specific data samples to enhance their performance in highly specific fields.
- These models can outperform generic LLMs in tasks related to their specific domain, such as radiology, genomics, or complex scientific text extraction.
- Retrieval-augmented generation (RAG) models enhance LLMs by retrieving and incorporating information from external knowledge bases, addressing inaccuracies and hallucinations, and providing up-to-date, factual, and source-attributed content.
By Modality
- Unimodal models: Trained exclusively on text data.
- Multimodal models: Can process and generate multiple data types, such as text, images, and speech.
By Language Breadth
- Monolingual models are trained on and generate text in a single language.
- Multilingual models can understand and generate text in multiple languages, which is particularly useful for applications requiring cross-lingual capabilities.
These categorizations provide a framework for understanding the different types of LLMs based on their training objectives, the kind of data they are trained on, and the range of languages they support.
What were significant milestones in LLM evolution?
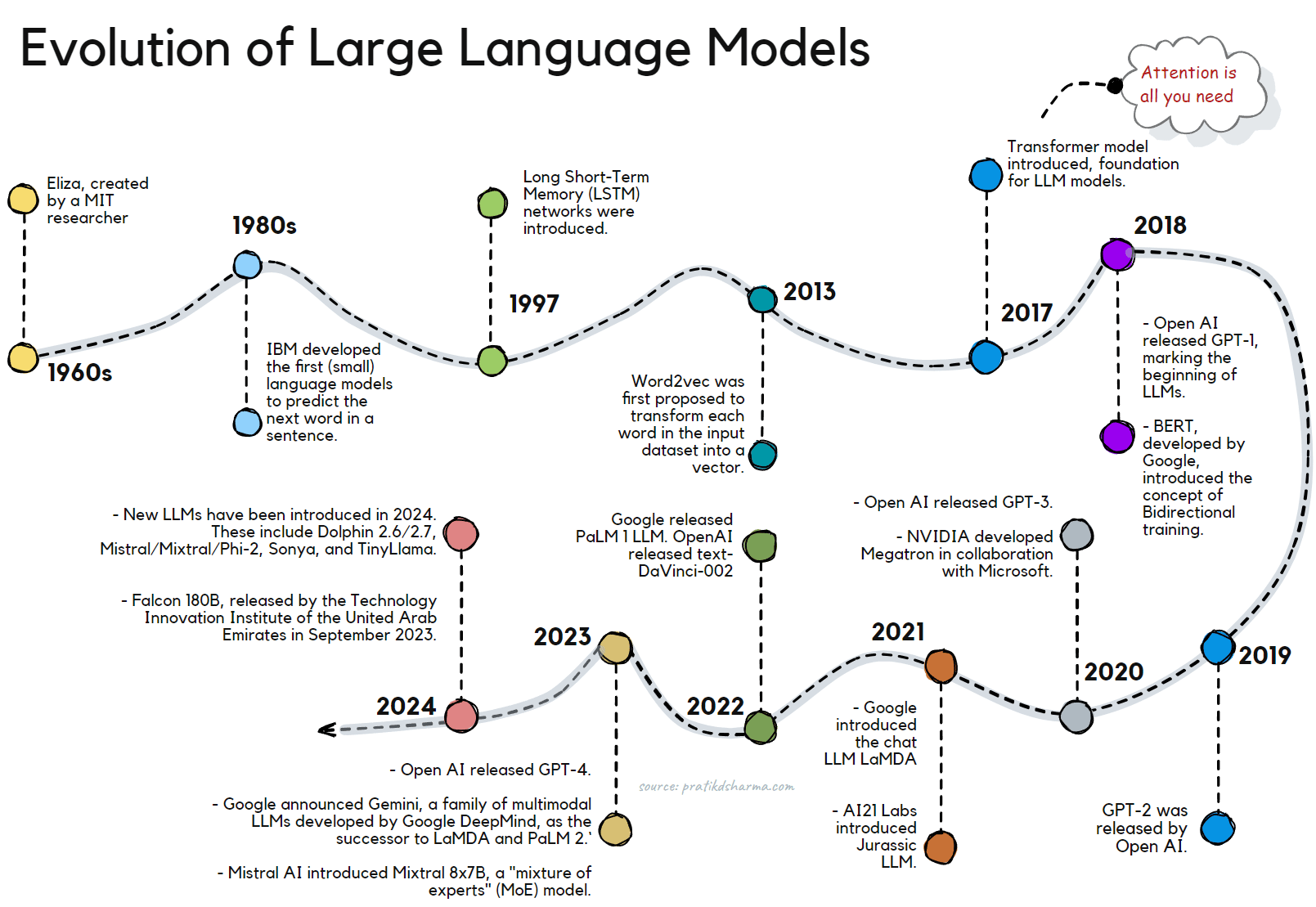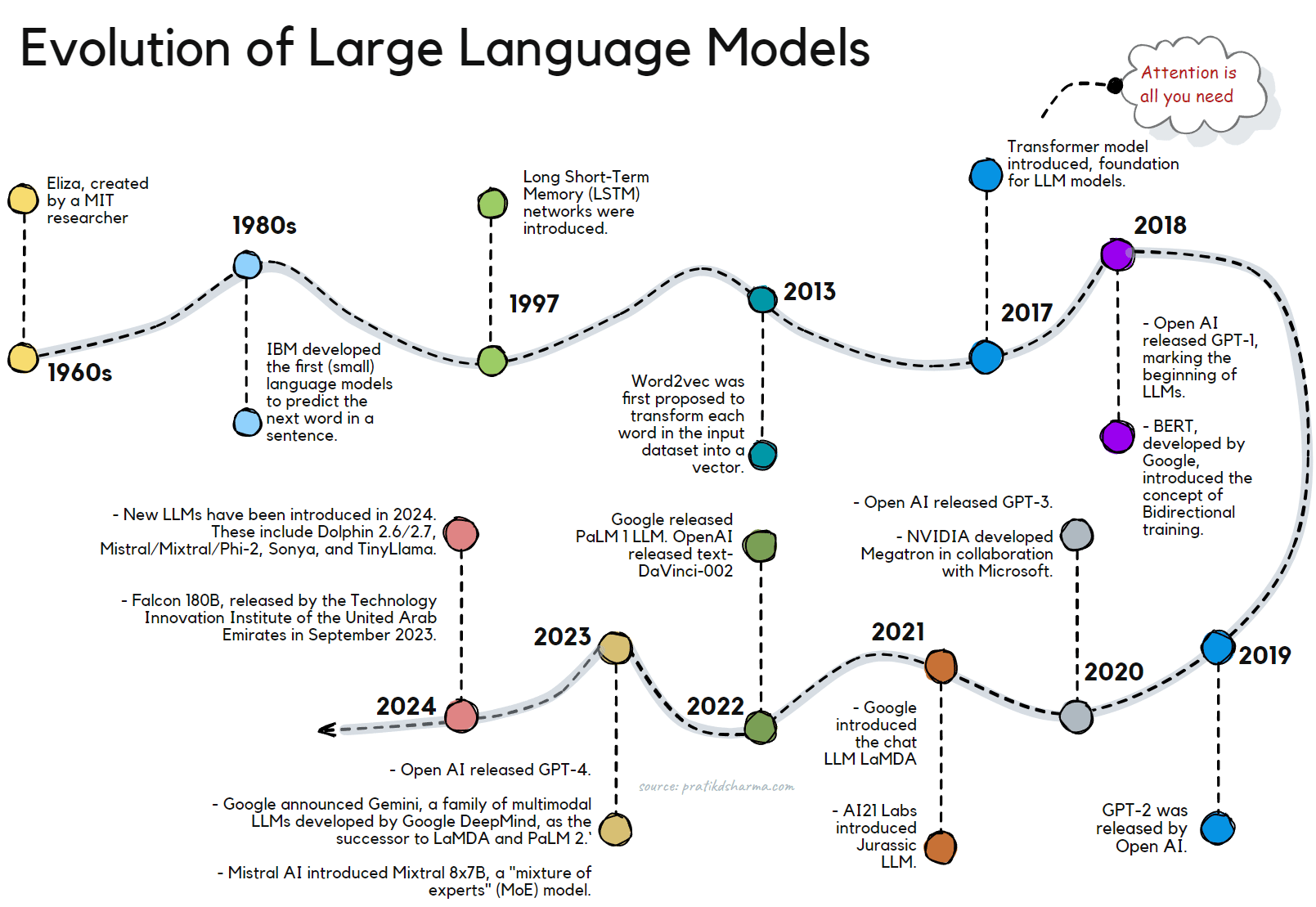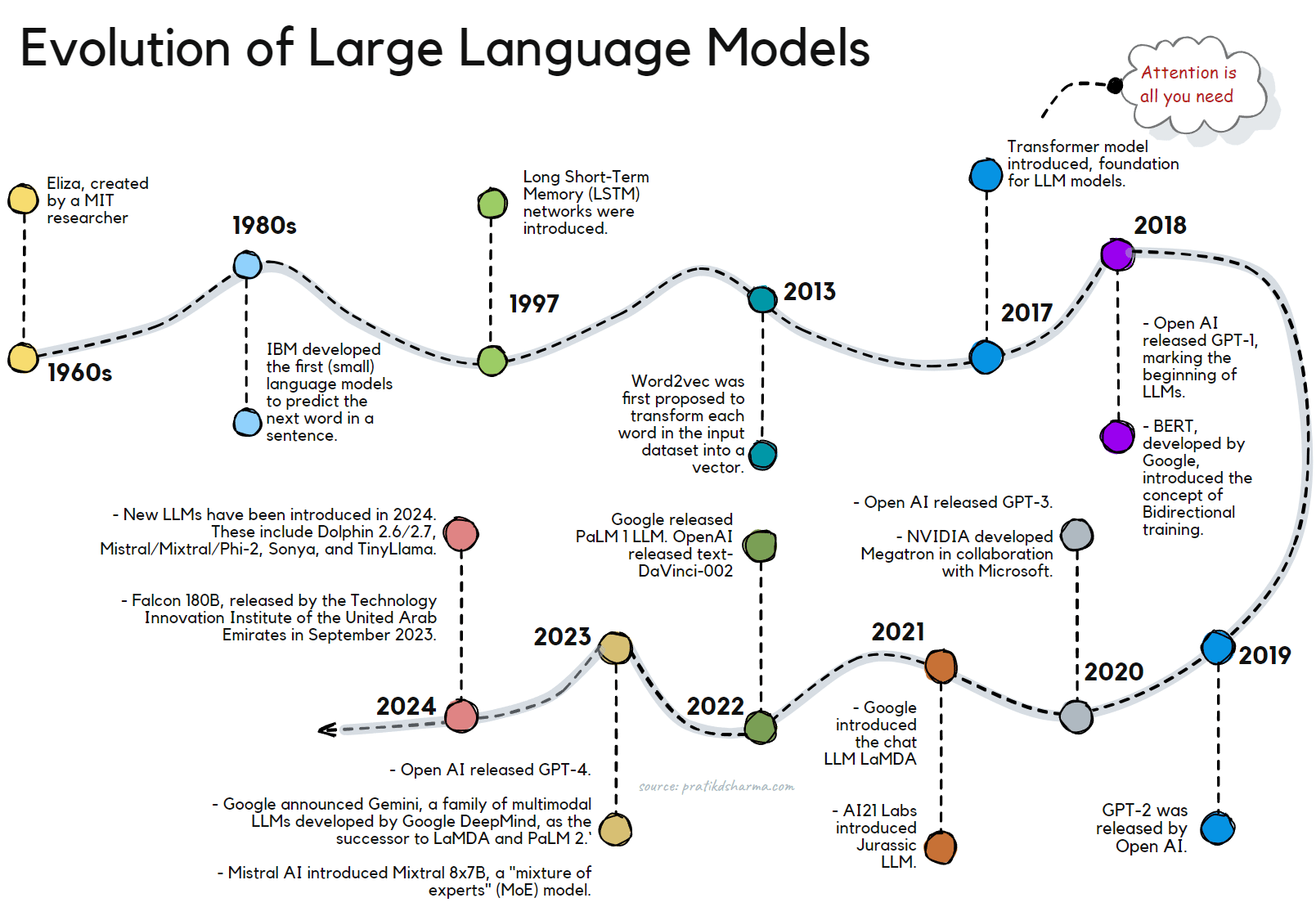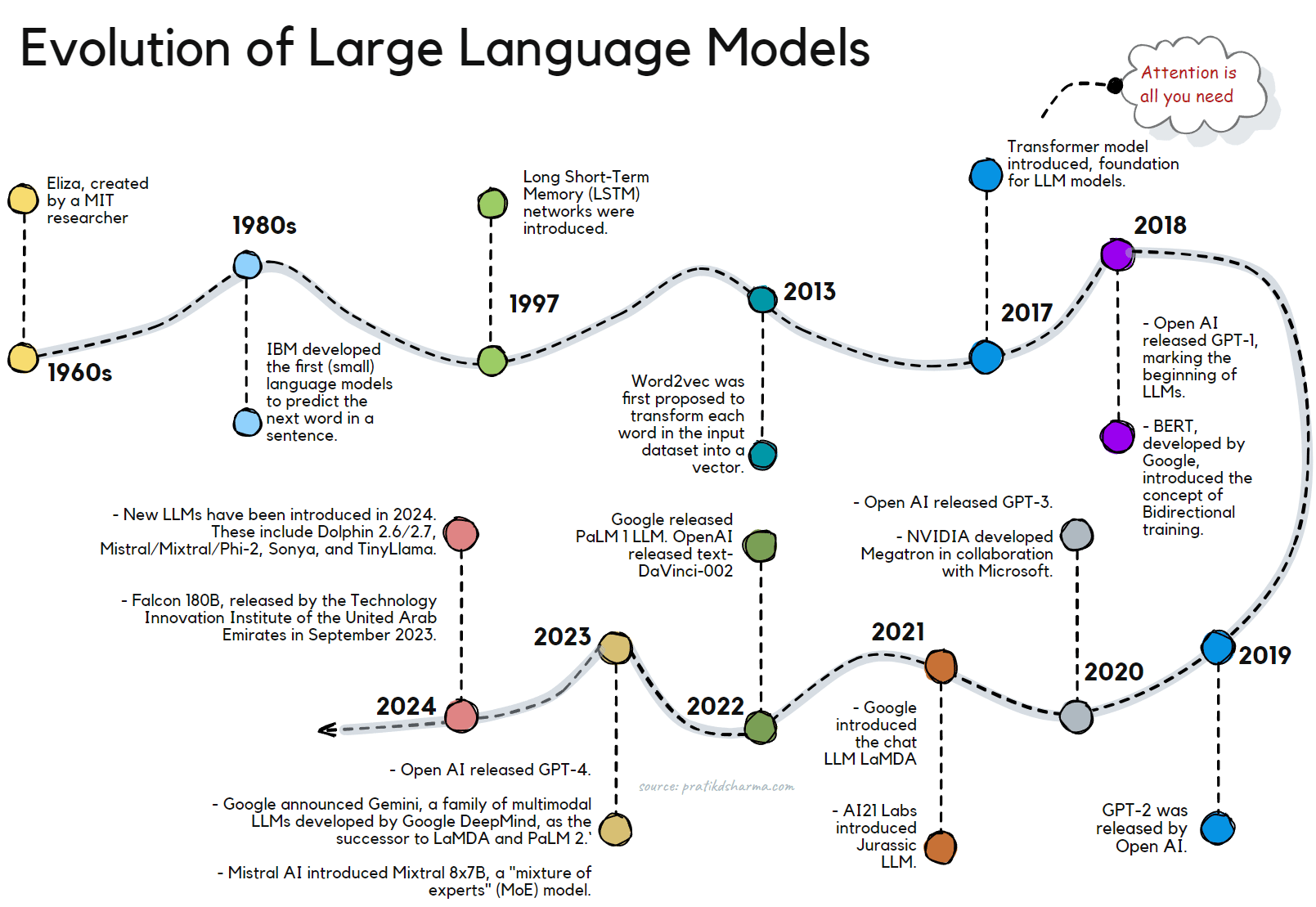
Evolution of Large Language Models (LLMs).
Significant milestones have marked the evolution of Large Language Models (LLMs). Here is a timeline of key developments:
- 1960s: The first-ever chatbot, Eliza, was created by MIT researcher Joseph Weizenbaum. This marked the beginning of research into natural language processing (NLP) and the development of LLMs.
- 1980s: IBM started the development of the first (small) language models designed to predict the next word in a sentence.
- 1997: Long Short-Term Memory (LSTM) networks were introduced. Their advent resulted in deeper, more complex neural networks that could handle more data.
- 2013: Word2vec was first proposed to transform each word in the input dataset into a vector. This marked a significant step in converting texts into numbers and capturing the semantic relevance of words.
- 2017: A breakthrough was made when Google Brain released a paper called "Attention Is All You Need," introducing the Transformer model, which became the foundation for many LLMs.
- 2018: OpenAI released GPT-1, marking the beginning of the GPT series of LLMs. BERT (Bidirectional Encoder Representations from Transformers), developed by Google, was a significant milestone in the evolution of LLMs. It introduced the concept of bidirectional training, which allows the model to understand the context of a word based on all of its surroundings (left and right of the word).
- 2019: GPT-2 was released by OpenAI.
- 2020: GPT-3 was released by OpenAI, reshaping perceptions of what LLMs can achieve. In the same year, NVIDIA developed Megatron, the forerunner to Nemo, in collaboration with Microsoft. AI21 Labs also introduced its LLM-powered grammar and writing checker, Wordtune.
- 2021: Google introduced the chat LLM LaMDA, and AI21 Labs introduced Jurassic LLM.
- 2022: Google released PaLM 1 LLM. OpenAI released text-DaVinci-002.
- 2023: OpenAI releases GPT-4. Google announces Gemini, a family of multimodal LLMs developed by Google DeepMind, as the successor to LaMDA and PaLM 2. Gemini comprises Gemini Ultra, Gemini Pro, and Gemini Nano. Mistral AI, a European start-up, introduces Mixtral 8x7B, a "mixture of experts" (MoE) model with open weights that reportedly matches OpenAI's GPT-3.5. Google rolls out Gemini 1.0 across a range of products and platforms. Mistral AI integrates its 7B model with Google Cloud's Vertex AI.
- 2024: Several new LLMs have been introduced in 2024. These include Dolphin 2.6/2.7, Mistral/Mixtral/Phi-2, Sonya, and TinyLlama [source]. Another notable model is Falcon 180B, released by the Technology Innovation Institute of the United Arab Emirates in September 2023. Falcon 180B is trained on 180 billion parameters and 3.5 trillion tokens, and it has outperformed LLaMA 2 and GPT-3.5 in various NLP tasks [source].
What are the applications of Large Language Models?
As discussed, Large Language Models use deep learning techniques to understand, generate, and predict new content. Integrating machine learning and deep learning techniques enables LLMs to understand, generate, and predict new content, allowing for innovative applications in various fields.
Machine learning's adaptability and learning capabilities significantly enhance the performance of these models. Once trained, LLMs can be used for different practical purposes, including answering questions, generating new text, summarizing text, and performing sentiment analysis.

Summarizing: As foundation models, LLMs can condense long text into shorter summaries, capturing the main points and ideas. This can be particularly useful in areas such as research, where LLMs can summarize complex reports or articles. They can also generate meeting summaries and transcriptions in a business setting.
Inferring: LLMs can infer or predict the next word or sequence of words in a sentence, which is fundamental to their ability to generate coherent and contextually relevant text. They can also infer the sentiment of a piece of text, a capability used in sentiment analysis.
Transforming: LLMs can transform text in various ways, such as translating it into different languages, rewriting sentences for clarity, or converting complex, domain-specific terminology into simpler language.
Expanding: LLMs can expand on a prompt to generate new, coherent text in addition to the above use cases. This can generate new ideas or content, such as writing articles or stories. They can also expand on a user's query to provide detailed answers or explanations.
If you're interested in understanding how we use Open AI API for the above tasks, you can read:

Decoding ChatGPT: The Ultimate Guide to LLM Mastery | by Pratik Sharma
Industry-Specific Applications
Bioinformatics and Healthcare: In the healthcare sector, LLMs can process and interpret vast amounts of medical literature, assist in clinical decision-making, and provide personalized medical information to patients and healthcare professionals.
Legal Document Review and Analysis: LLMs are used in the legal industry for document review and analysis, helping to identify relevant information within large volumes of legal texts and preparing legal documents and case research.
Customer Support and Marketing Content: LLMs often provide 24/7 customer support through chatbots and conversational AI assistants, answering customer queries and automating routine interactions. They also assist in generating marketing content, ensuring consistent and high-quality material tailored to specific audiences and languages.
Education: In education, LLMs tailor learning experiences, enhance analytics, and create interactive simulations. They can provide personalized learning materials, assist in grading and feedback, and create immersive educational experiences that adapt to the learner's needs and progress.
Finance: LLMs can automate financial transactions and data processing in the finance sector, reducing manual effort and increasing efficiency. They can also assist in fraud detection, risk assessment, and other complex tasks that require the analysis of large volumes of data.
Creative Writing: LLMs show promise in creative writing, including fiction and poetry. They can assist authors with character development, plot creation, and overcoming writer's block. They can also generate writing prompts based on story concepts to spark the author's creativity. However, fully automated fiction generation by LLMs remains challenging due to the complexity of crafting engaging narratives and characters.
Multilingual Customer Service: Companies use LLM-powered chatbots to provide instant support in multiple languages, ensuring a seamless customer experience. These chatbots can understand and respond to customer queries, automate routine interactions, and provide personalized assistance based on the customer's needs and preferences.
Code Generation: LLMs can generate code in various programming languages from natural language descriptions, promising to expedite development processes. Models like OpenAI's Codex and Amazon's CodeWhisperer are already integrated into tools like GitHub Copilot, offering intelligent code completion and generation capabilities. LLMs can efficiently produce functions, classes, SQL queries, and more, translating developer ideas into code.
What are the Challenges of Large Language Models?
The challenges of Large language models include ethical issues (authorship, plagiarism, biases), privacy concerns (data leakage), performance limitations, interpretability difficulties, resource constraints in fine-tuning, evaluation challenges, misinformation and impersonation risks, and hallucination.

Ethical Concerns
- Large Language Models like ChatGPT can generate text that is difficult to distinguish from human-written content, raising concerns about authorship and plagiarism.
- They can also perpetuate or amplify social biases in their training data. Ethical issues include potential misuse, such as generating harmful or manipulative content (source).
User Data Privacy
- Such models are trained on vast amounts of web-collected data, which may contain sensitive personal information, leading to privacy leakage concerns.
- ProPILE, a probing tool, has been developed to assess the risk of personally identifiable information (PII) leakage (source).
Performance Limitations
- While these models have shown improvements in text generation, they may still struggle with tasks like recalling previous tokens or comparing tokens in a sequence.
- There are inherent limitations in the alignment of LLMs, meaning that even with tuning, there is a risk of models exhibiting undesired behaviors when prompted.
Bias and Fairness
- These models can inherit and propagate biases from their training datasets, leading to unfair outcomes or discriminatory content.
- The bias challenge involves training data, model specifications, algorithmic constraints, product design, and policy decisions.
Interpretability
- The complexity makes it difficult to understand how they generate their outputs, a barrier to ensuring their reliability and trustworthiness.
- Improving interpretability includes developing probing tools and theoretical frameworks to understand model behavior better.
Resource Constraints
- Fine-tuning LLMs requires significant computational resources, which can be a barrier, especially for models with a large number of parameters ranging from millions to billions.
- When fine-tuning a small model is viable but fine-tuning a larger one is not, techniques like up-scaling can capture many benefits of fine-tuning the larger one due to resource constraints.
Model Evaluation
Evaluating the effectiveness of fine-tuned LLMs presents challenges, requiring a multifaceted approach to their assessment.
Misinformation
- LLMs also face challenges related to misinformation, as they can inadvertently generate or propagate false or misleading content. For example, OpenAI is tackling misinformation by implementing a multi-faceted strategy that includes:
- Model Construction and Access: Carefully controlling the construction and access to models to prevent misuse.
- Content Dissemination: Monitoring and controlling the dissemination of content generated by LLMs.
- Belief Formation: Studying how LLMs influence belief formation and taking steps to mitigate any negative impacts.
- Digital Watermarking: Exploring the use of digital watermarking to identify content generated by LLMs.
- Partnerships: Collaborating with external organizations to address misinformation challenges.
- Impersonation Prevention: Implementing measures to prevent LLMs from being used to impersonate individuals.
- Provenance Classifier: Develop a provenance classifier to identify the source of generated content.
- Directing Voting Queries: Directing voting queries to the user ensures the model's output aligns with the user's intent.
- Policy Updates: Regularly updating policies to address emerging misinformation threats.
Hallucination
Hallucination is a significant challenge in Large Language Models where they generate plausible but incorrect or nonsensical information. This issue arises due to the models' reliance on patterns in the training data rather than factual accuracy or real-world knowledge. Hallucinations can manifest in various forms, such as inventing non-existent facts, misrepresenting real events, or creating fictional entities. These errors pose risks in applications where factual accuracy is critical, such as in educational, professional, or decision-making contexts.
How does the future of LLMs look like?

The market for Large Language Models (LLMs) is experiencing rapid growth and is projected to continue expanding in the coming years. A report by Valuates Reports forecasts the LLM market to grow from $10.5 billion in 2022 to $40.8 billion by 2029, with a Compound Annual Growth Rate (CAGR) of 21.4% [source]. The rising need for Natural Language Processing applications across various industries drives this growth.
Furthermore, the generative AI market, which includes LLMs, is projected to grow from $11.3 billion in 2023 to $51.8 billion by 2028 at a CAGR of 35.6% [source]. This growth is attributed to cloud storage innovation, the evolution of AI and deep learning, and the rise in content creation and creative applications.
The future of large language models is tied to advancements in the variety of natural language processing and AI technologies. This indicates a strong LLM market trajectory, increasing adoption and integration into various sectors, including healthcare, finance, education, and customer service. The development of small language models (SLMs), which could offer more efficiency and versatility due to their reduced size, is also anticipated.
As we move further into 2024 and beyond, LLMs are expected to become even more integrated into our daily lives, with potential applications ranging from personal assistants to advanced analytics in market research. The ongoing research and development in this field suggest that LLMs will continue to evolve, becoming more accurate, contextually aware, and capable of handling complex tasks across multiple languages and domains.
What are some examples of large language models?
Here is a summary of some prominent large language models (LLMs) in 2024, segmented by open-source and closed-source:
Open-Source LLMs
- Llama 2 - It was released by Meta in 2023. It has up to 70 billion parameters and is designed for general natural language tasks like question answering and text summarization.
- Falcon 180B - With 180 billion parameters, this is one of the largest open-source LLMs. Shows strong performance on language tasks and is still expanding.
- Bloom - Developed through a collaborative global effort over 2022. Specializes in autoregressive text generation and extending text prompts.
- Mistral - 7 billion parameter multilingual model covering over 100 languages. Can perform cross-lingual transfer and shows promising few-shot learning capabilities.
Closed-Source Commercial LLMs
- GPT-4 - The latest model in OpenAI's GPT series released in 2023. It has over 100 billion parameters and specializes in creative applications like writing stories and computer code.
- Bard - Google's conversational AI assistant launched in 2023. Still in limited preview, it aims to provide helpful, high-quality responses to natural language queries.
- Claude - Developed by Anthropic to be helpful, harmless, and honest. Has been trained with Constitutional AI techniques to improve safety.
- PaLM - Released by Google in 2022 with over 500 billion parameters. State-of-the-art performance on many NLP datasets.
The open-source models offer transparency and customizability, while the closed-source commercial models promise advanced capabilities backed by structured support. Both categories continue to evolve rapidly.
Conclusion
Large Language Models (LLMs) have emerged as a transformative technology in artificial intelligence, unlocking new capabilities in generating human-like text and powering innovations across industries. The future of LLMs looks promising, with advancements aiming to address current limitations such as factual unreliability and static knowledge. This indicates a strong LLM market trajectory, increasing adoption and integration into various sectors, including healthcare, finance, education, and customer service.
However, as with any rapidly evolving technology, LLMs also pose complex challenges around ethics, privacy, security, bias, and hallucination that must be carefully considered. Measures such as carefully controlling the construction and access to models, monitoring and controlling the dissemination of content generated by LLMs, and collaborating with external organizations to address misinformation are being implemented to mitigate these challenges.
In conclusion, Large Language Models and generative AI are reshaping AI applications and transforming industries. Still, their ethical and practical implications must be carefully managed to ensure their responsible and beneficial integration into various sectors.
Fuel your AI curiosity! Get notified as soon as we publish new articles like this one, packed with the latest LLM news, practical applications, and expert insights. Subscribe to the newsletter and keep your AI knowledge tank topped up. 🚀📚

Stay Informed, Stay Inspired.
Join the newsletter to receive the latest updates in your inbox.
🚫 No spam. Unsubscribe anytime .

{kind=link}