LLMs in 2023: Advancements, Challenges, and The Future
Explore the LLM landscape 2023 with ChatGPT, Llama-2, Claude-2, Gemini AI, Mistral7B, & India's breakthroughs. Anticipate the future of these AI marvels while delving into the challenges they face.

2023 stands as a watershed year for Large Language Models (LLMs). As we approach the horizon of 2024, it's clear that the past year wasn't just a stepping stone but a launchpad for a paradigm shift in AI communication and interaction. Industry giants like OpenAI and Meta scaled new heights, with ChatGPT-4 achieving unprecedented feats in multimodal processing and contextual understanding. Meanwhile, rising stars like Mistral AI's MoE 8x7B shattered efficiency barriers, while Alibaba's Qwen series and the multilingual Yi models blazed a trail on the global stage.
But 2023 wasn't just about technical prowess. It was a year of bold leaps in reasoning and logic, with LLMs like Claude 2.1 demonstrating remarkable skills in tasks once considered the exclusive domain of humans. Open-source initiatives like Llama-2 democratized access to this cutting-edge technology, fostering widespread collaboration and fueling innovation.
This analysis dives deep into these triumphant advancements, charting the future course of natural language processing and generation and critically examining the ethical landscape that comes with such unparalleled power. We'll grapple with the delicate balance between progress and responsibility, ensuring that these LLMs become beacons of positive change in the world.
Furthermore, we'll shine a light on the global tapestry of LLM development, highlighting the crucial contributions of emerging players like India. Their dedication to building language models tailored to diverse needs and linguistic landscapes showcases this field's collaborative and inclusive nature.
So, buckle up, for as we turn the page to 2024, the story of LLMs is far from over. Get ready for a thrilling exploration of groundbreaking achievements, profound challenges, and the boundless potential of AI to reshape the way we communicate and interact with the world around us.
ChatGPT & GPT-4: AI Redefines Communication & Interaction
OpenAI's ChatGPT, a generative AI chatbot based on the GPT-3.5 model, captivates users with natural and engaging conversations across diverse topics. Released in November 2022, ChatGPT has since integrated into various platforms and applications, displaying remarkable progress in multimodal capabilities and advanced contextual understanding.
In November 2023, ChatGPT and GPT-4 recently received a significant update that enhanced their capabilities in several key areas. These improvements include:
- Supercharged GPT-4 Turbo: Vastly expanded knowledge (April 2023!), handles prompts up to 128k tokens (think 300 book pages!), follows instructions like a pro, and costs less for developers.
- Custom GPTs: Build your AI assistants without coding, share them on the GPT Store, and turn your skills into profit.
- Agent-like Assistants: Craft complex AI companions that understand intricate commands and leverage multiple tools to get things done.
- DALL-E 3 Unleashed: Text-to-image magic with built-in safety, plus goodbye editing existing images for extra security.
- Hear Your Words Come Alive: New text-to-speech voices and AI models perfect for audiobooks, assistants, and language learning.
- Copyright Shield: Business-friendly protection from copyright claims, use OpenAI products confidently.
- Custom Models for Your Needs: Partner with OpenAI experts to build AI models that understand your business inside and out.
- Simpler, Smarter ChatGPT: No more menu juggling; the model picks the perfect tool for every task.
- Whisper Gets Even Better: The open-source speech recognition model gets a major upgrade and listens clearer than ever.
- Double the Speed: Paying GPT-4 users get twice the tokens per minute and supercharges your AI workflow.
Multimodal Capabilities and Enhanced Contextual Understanding
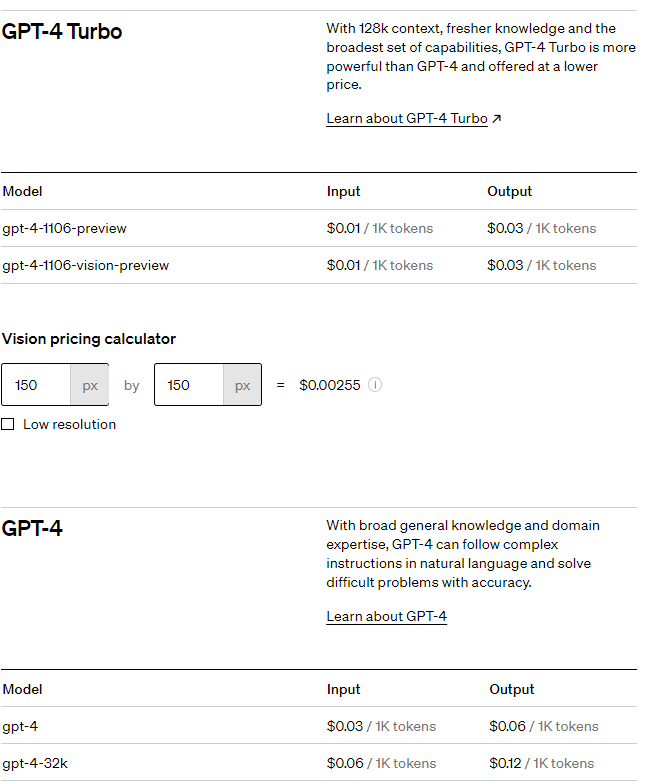
- GPT-4 Beyond Text: GPT-4, unlike its predecessors, can process and respond to multimodal inputs, including images and code. This opens up new possibilities for applications in creative tasks, design, and programming.
- 128k Context Window: GPT-4 can access and process a significantly larger context window (128k tokens) than GPT-3.5 (2048 tokens). This allows for a deeper understanding of the conversation and more relevant and coherent responses.
- Model Alignment Enhancements: GPT-4 incorporates significant advancements in model alignment for safer outputs. These include mechanisms to align model goals with human values and mitigate the risk of biased or harmful results.
- ChatGPT Plugins: These act as "tools" for the model, allowing it to interact with third-party applications and access specialized information. This significantly expands ChatGPT's capabilities and enables a broader range of applications.
GPT-4's Improvements
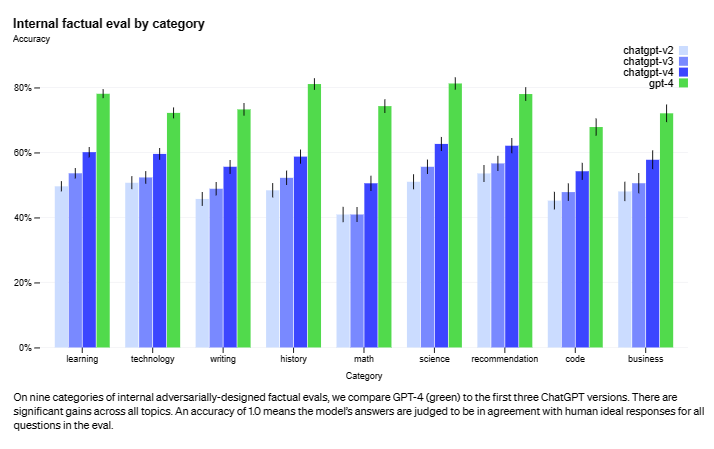
- Reasoning and Logic Advancements: GPT-4 showcases significant progress in reasoning and logic tasks. OpenAI scores within the top 10% range on simulated bar exams, compared to GPT-3.5's performance in the bottom 10%.
- Generating Functional Code: Users report success developing working code for simple arcade games using GPT-4, indicating improved comprehension and code generation.
- Reduced Bias and Misinformation: The increased context window and model alignment efforts in GPT-4 contribute to a reduction in factual errors and biased outputs.
The Future of ChatGPT and GPT-4
These models' rapid development and adoption suggest a promising future for AI-powered communication and interaction. Some potential future applications include:
- Enhanced Customer Service: AI chatbots powered by GPT-4 and ChatGPT can provide more personalized and efficient customer service experiences.
- Personalized Education: The models can adapt to individual learning styles and provide tailored educational content.
- Creative Content Generation: GPT-4's multimodal capabilities open doors for AI-assisted video editing, music composition, and other creative endeavors.
- Scientific Research: The models can assist researchers in data analysis, hypothesis generation, and literature review.
- Expanded Functionality through Plugins: ChatGPT plugins enable a more comprehensive range of applications, such as retrieving real-time information, accessing knowledge bases, and assisting with actions.
However, challenges remain, such as ensuring ethical development and usage, mitigating potential biases, and addressing the societal impact of these powerful language models. OpenAI and other developers are responsible for addressing these challenges and ensuring this technology's responsible development and deployment.
Mistral AI's MoE 8x7B: Efficiency & Performance Reimagined
Mistral AI's MoE 8x7B, launched in December 2023, has sent shockwaves through the LLM landscape. This decoder-only model, powered by a cutting-edge Sparse Mixture-of-Experts (MoE) framework, shatters efficiency barriers. Despite its 46.7 billion parameters, it operates with only 12.9 billion per token, outperforming benchmark rivals like Llama-2 70B and boasting a 6x faster inference speed.
But MoE 8x7B's brilliance extends beyond mere speed. It showcases exceptional multilingual capabilities, dominating the MMLU test and surpassing Llama models across diverse languages. Additionally, its lower bias scores in categories like gender, profession, and religion suggest significantly reducing algorithmic prejudice.
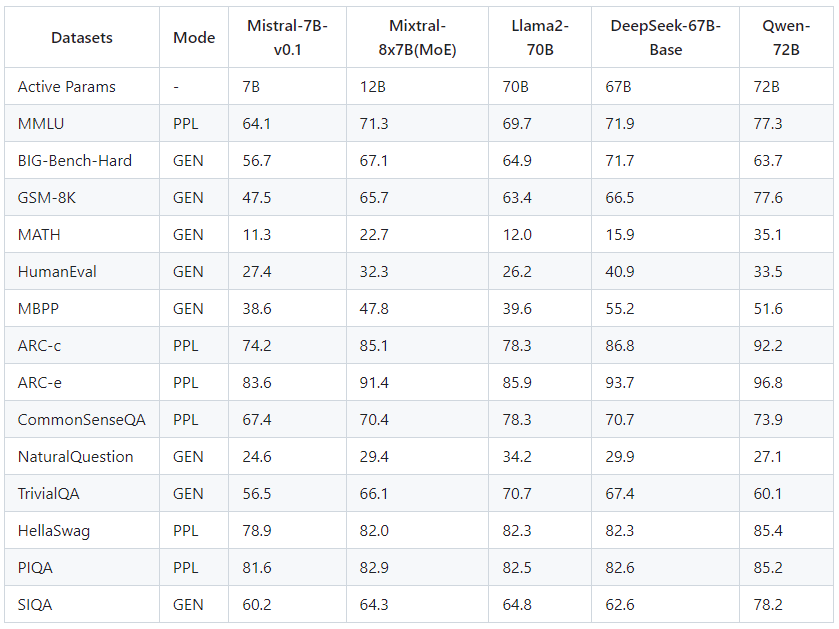
The fine-tuned Instruct variant has clinched a commendable MT-Bench score, further solidifying MoE 8x7B's prowess.
Mistral AI offers flexible access options: a pay-as-you-go API and open-source models readily available on Hugging Face or their documentation. Deployment is seamless, with cloud and on-premise compatibility through TensorRT-LLM or vLLM.
The open-source nature of MoE 8x7B empowers researchers and developers to delve into its depths through the comprehensive MixtralKit GitHub repository. This fosters exploration and innovation, potentially leading to exciting advancements:
- Further efficiency gains: The MoE framework holds immense potential for optimization, possibly pushing efficiency boundaries even further. This could lead to LLMs with smaller parameter footprints and even faster processing.
- Enhanced multilingual capabilities: MoE 8x7B's multilingual abilities could be amplified with ongoing research and development, potentially mastering even more languages and nuances.
- Reduced bias: Continued efforts to mitigate bias could refine MoE 8x7B's fairness and inclusivity, paving the way for responsible and ethical AI applications.
- Domain-specific specialization: The modular nature of MoE could enable fine-tuning for specific domains like healthcare, finance, or legal tasks, resulting in specialized LLMs with even more significant impact.
MoE 8x7B is a potent force in the present, and its prospects are equally dazzling. Its combination of efficiency, performance, and diverse capabilities, coupled with the power of open-source development, paves the way for a future where LLMs are not just powerful but accessible, responsible, and transformative across various domains.
Llama-2: Open-Sourcing the Future of AI-Language Models
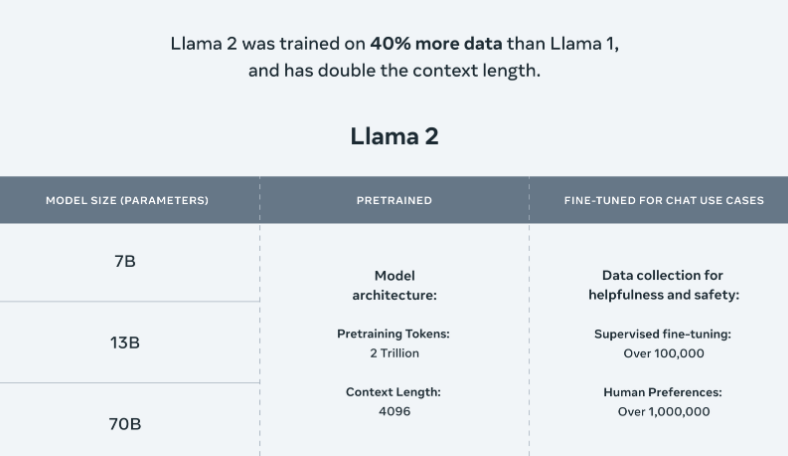
Building upon their inaugural model, Meta launched Llama-2 in July 2023, an enhanced open-source LLM designed for versatility and performance. Released in collaboration with Microsoft, Llama-2 marks Meta's commitment to democratizing AI research and fostering global collaboration. This open-source approach unlocks innovation across diverse fields.
Key Features
- Massive dataset: Trained on 2 trillion tokens
- Flexible parameters: Scales from 7 to 70 billion
- Enhanced capabilities: 40% more data and twice the context length than Llama-1
- Impressive efficiency: Matches GPT-4's summarization accuracy with 30% fewer resources
Llama-2 Long
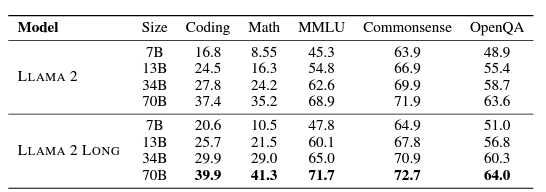
- Specialized variant for long and complex queries
- Additional 400 billion tokens
- Context length of >32k
Open-Source Commitment
Llama-2 embodies Meta's dedication to responsible and collaborative AI development. Its potential to accelerate innovation across diverse fields is undeniable, promising a future where language models empower researchers and all of us.
Meet the Llama Family
Llama-2 comes in three versions, each with its strengths. The 7 billion parameter version is a versatile all-rounder, while the 13 billion and 70 billion versions pack extra power for specialized tasks. And for those wanting to chat with Llama, there's even a fine-tuned "chat" version ready for conversation.
From AI Assistants to Code Generation
Think of all the possibilities! Qualcomm and Meta are working to bring Llama-2 to our devices, powering intelligent assistants, productivity tools, and even creative software. Imagine your phone writing emails, drafting documents, or even composing music on the fly!
But Llama-2's reach extends beyond our gadgets. Researchers are using it to tackle complex challenges like medicine and mathematics. Code Llama, a specialized version, can even understand and write code in multiple languages, making developers' lives easier.
The Road Ahead
While powerful, Llama-2 is still learning. Its ultimate goal is to achieve Artificial General Intelligence (AGI), meaning it can handle any intellectual task a human can. But this requires overcoming challenges like reasoning, common sense, and dealing with unexpected situations.
Meta is committed to responsible development. They're working on safety measures, building partnerships, and empowering the developer community to ensure Llama-2 is used for good. They're also tackling ethical concerns like bias and misuse head-on.
Llama-2 is just the beginning. It's a glimpse into a future where AI becomes a helpful companion, unlocking new possibilities in every aspect of our lives.
Beyond GPT: Claude 2.1 Charts a New Course
The LLM landscape in 2023 witnessed remarkable leaps, particularly with the arrival of Claude 2.1 by Google-backed Anthropic. This powerhouse model exemplifies the advancements in LLM capabilities and applications. Let's delve into these developments, exploring their impact on various industries and the future of AI.
Key Highlights of Claude 2.1:
- Unprecedented Context: Claude 2.1 boasts a groundbreaking 200K token context window, doubling its predecessor's capacity. This empowers the model to process complex data, large documents, and intricate datasets.
- Enhanced Accuracy: The expansive context window translates to a 50% reduction in hallucination rates compared to Claude 2.0. This enhanced reliability makes it ideal for tasks demanding precision, opening avenues across diverse fields.
- Tool-Powered Precision: Claude 2.1 integrates with user-defined APIs and tools, enabling tasks like complex calculations, structured API calls, and database/web searches. This empowers developers and users to leverage its capabilities in unique ways.
- Developer-Friendly Features: The introduction of the Workbench facilitates efficient testing and optimization. System prompts further enhance performance and tailor responses, giving developers greater control.
Adoptions and Industry Impact:
- Diverse Applications: Claude has found applications in scholarly article translation, business plan creation, and intricate contract analysis. Its enhanced context and accuracy make it particularly valuable for large document tasks.
- Competitive Edge: Claude 2.1's advancements keep it at par with other prominent LLMs like OpenAI's GPT series. While each model has its own approach, Claude's unique features and improvements solidify its position in the rapidly evolving LLM landscape.
Future Implications and Trends:
- Continuous Evolution: The LLM industry is constantly pushing boundaries, with models like Claude 2.1 paving the way for further improvements in accuracy, latency, and API integration.
- Large Context Window - A Double-Edged Sword? While the expansive context window marks a significant leap, its effectiveness in processing large data sets compared to smaller chunks needs further evaluation. Studies have shown potential performance declines with increasing document depth, highlighting areas for future optimization.
- Cost Efficiency and Accessibility: Extensive development and testing with Claude 2.1 may incur costs. However, its pricing structure is designed to improve cost-efficiency for diverse user groups.
- Tool Integration and Beyond: The beta feature of external tools opens doors to intricate interactions and integrations. This could potentially lead to developing of more dynamic and adaptable AI applications.
In conclusion, the arrival of Claude 2.1 marks a significant milestone in the evolution of LLMs. Its advanced capabilities and unique features make it a powerful tool with diverse applications. As the LLM landscape continues to evolve, Claude 2.1 serves as a testament to the growing potential of these models and their impact on various industries.
Google's Gemini AI: A New Era of Multimodality
In 2023, Google's DeepMind and Brain AI labs collaboratively launched Gemini AI, a significant advancement in AI technology. Gemini AI stands out for its ability to process and integrate diverse data types, including text, images, audio, and video.
Developments and Implementations
- Google introduced three Gemini model versions: Ultra, Pro, and Nano. The Ultra model excels in complex, multi-data-type tasks. The Pro model offers a balance of performance and efficiency for various applications. The Nano model, designed for on-device use, features hardware enhancements for offline use, particularly in devices like the Pixel 8 Pro.
- Google upgraded its AI chatbot, Bard, to operate on Gemini Pro and plans to integrate Gemini Pro into its products, including Search, Ads, Chrome, and Duet AI (encompassing Gmail and Google Docs). The latest Pixel 8 Pro will employ Gemini Nano for features like audio file summarization and quick text message responses.
- Using open-source APIs, Google aims to grant third-party Android developers access to Gemini Nano via AICore service on Android 14.
Gemini AI’s Multimodal Capabilities and Platform Versatility
- Gemini AI utilizes a transformer-based architecture and is proficient in processing and merging various data types. Its multimodal encoder handles individual modalities, a cross-modal attention network discerns inter-data relationships and a multimodal decoder performs tasks like image captioning and code generation.
- Gemini AI's architecture enables handling complex real-world applications, particularly in education, where it can analyze and correct solutions in subjects like physics. It powers agents like AlphaCode 2, showcasing superior performance in competitive programming contests.
- Gemini Nano extends AI's reach to standard devices, excelling in tasks like summarization, reading comprehension, coding, and STEM-related problems. This enables devices with lower memory to access advanced AI features, broadening the availability of sophisticated AI.
The Future of Gemini AI
- Gemini AI's launch in 2023 marked a pivotal moment in AI development, ushering in a phase of rapid growth and potential. Its multimodal functions and platform adaptability make it a versatile tool for various applications.
- Google's commitment to integrating Gemini AI into its ecosystem and opening access to developers and businesses forecasts a future with seamless AI integration in everyday technologies. The continuous evolution of models like Gemini AI underscores the importance of sustained research and development to address challenges and ensure AI technologies' ethical, responsible use5.
Alibaba's Qwen & Yi Series: The Rise of Eastern LLMs
In 2023, the Yi Series by 01.AI and Alibaba's Qwen showcased significant advances in large language models (LLMs).
Yi Series
- Architecture: Adopts LLaMA's architecture, boosting development efficiency.
- Bilingual Capabilities: The Yi series ranked second in both English and Chinese language capabilities. For English, it ranked just behind GPT-4 on the AlpacaEval Leaderboard, and for Chinese, it also followed GPT-4 on the SuperCLUE leaderboard.
- Model Variants:
- Base models: Yi-6B, Yi-34B, Yi-6B-200K, Yi-34B-200K.
- Chat models: Yi-34B-Chat, Yi-34B-Chat-4bits, Yi-34B-Chat-8bits, Yi-6B-Chat, Yi-6B-Chat-4bits, Yi-6B-Chat-8bits.
- Licensing: Available for various uses under a community license agreement.
Qwen Series
- Open-Source Initiative: Features models like Qwen-1.8B and Qwen-72B and chat variants accessible on platforms like GitHub and Hugging Face.
- Performance: Qwen-7B outperforms similar and more prominent models in benchmarks.
- Expansion: Enhances Alibaba's AI solutions with audio models.
Both series' diverse model variants and strong performances indicate a promising future despite challenges balancing response diversity and accuracy.
India's AI Leap: Making Strides in Large Language
Here is a summary of India's efforts in Large Language Models (LLMs) in 2023:
- Bhashini: The Indian government launched the Bhashini project, an ambitious initiative to gather massive datasets in various Indian languages through crowdsourcing. This data forms the foundation for building future translation tools using large language models (LLMs) and promoting linguistic accessibility. Over 1000 pre-trained AI models are already available on the Bhashini platform.
- Krutrim: Krutrim Si Designs, led by Ola co-founder Bhavish Aggarwal, unveiled Krutrim, a sophisticated AI multimodal model. This model excels at understanding over 20 languages and generating content in 10 Indian languages, empowering communication and creative expression across diverse linguistic landscapes. Krutrim comes in the standard model and the more advanced Krutrim Pro.
- LLM360: A collaborative effort by Cerebras Systems, Petuum, and MBZUAI, LLM360 is an open-source framework designed to democratize LLM development. Two notable models emerged from this project: Amber, a seven-billion-parameter English LLM, and CrystalCoder, a model specializing in both English language and coding tasks.
- BharatGPT: CoRover.ai introduced BharatGPT, an Indian-built generative AI platform supporting 12+ Indian languages, further broadening the reach and possibilities of AI-powered communication within the country.
- OpenHathi: Sarvam AI made history with OpenHathi, the first open-source Hindi language model, a significant step towards making advanced AI technology more accessible and adaptable to specific regional needs.
- Dhenu: KissanAI's Dhenu, a large agricultural language model tailored for Indian farming practices, showcases the potential of LLMs to revolutionize specific sectors by understanding and responding to domain-specific queries in multiple languages, including English, Hindi, and Hinglish.
- Nvidia & Reliance LLM: A landmark collaboration between Nvidia and Reliance Industries resulted in a foundational large language model specifically designed for India, capable of comprehending and generating text in many Indian languages.
- High-powered Committee: Recognizing the growing importance of LLMs, the Indian government's Principal Scientific Advisor announced the formation of a "high-powered committee" to explore the strategic development and deployment of LLMs in India.
India's strides in AI technology development and adoption are noteworthy. These advancements are instrumental in overcoming linguistic barriers and democratizing AI for the country's diverse population. The construction of these models leverages deep learning methodologies, specifically neural networks. They can produce contextually appropriate and coherent text based on provided prompts or inputs.
Conclusion: Future of AI-Powered Communication
So, buckle up, fellow explorers!
Stay curious, ask questions, and join us as we delve deeper into the world of AI. Subscribe now and catch every twist and turn in this extraordinary saga - because in 2024, the future of AI promises to be anything but ordinary.

Stay Informed, Stay Inspired.
Join the newsletter to receive the latest updates in your inbox.
🚫 No spam. Unsubscribe anytime .

{kind=link}