Mastering Machine Learning for Classification (Part 2/2)
Explore advanced ML classification topics: deep learning, handling imbalanced data, model evaluation (AUC-ROC, Precision-Recall), and resources.

In the first part of the machine learning classification series, we delved into the fundamentals, exploring various classification tasks and discussing the most widely used classification algorithms. Building on that foundation, Part 2 aims to enhance your understanding by covering advanced topics, evaluation techniques, and essential tools and resources.
Evaluating a Classification Model
This section contains essential techniques and metrics for evaluating a classification model's performance. Understanding these evaluation methods is crucial for assessing how well your model generalizes to new, unseen data and identifying areas where it may need improvement.
We will explore various tools and metrics, including the confusion matrix, log loss, bias and variance, the holdout method, AUC-ROC curves, precision and recall, and the precision-recall curve.
Mastering these evaluation techniques will equip you to fine-tune your models and ensure they meet the specific requirements of your classification tasks.
Confusion Matrix
The confusion matrix visualizes a classification model's performance. It shows correct and incorrect predictions broken down by class.
The matrix has two dimensions: the actual values in the dataset and the predictions made by the model. By comparing the two, you can calculate a variety of evaluation metrics:
- Accuracy - This reflects overall model performance across all classes. It's the ratio of correctly predicted observations to the total observations.
- Precision - Indicates the ratio of true positives to all positives predicted by the model, highlighting the model's ability to return relevant instances.
- Recall - Measures the ratio of true positives to all actual positives, assessing the model's capability to find all relevant cases within a dataset.
- F1 score - Balance of precision and recall.
Confusion matrices allow you to identify patterns in incorrect predictions. For example, errors between certain classes may indicate the model struggles to differentiate between similar concepts.
Log Loss or Cross-Entropy Loss
Log loss (or cross-entropy loss) is a commonly used loss function for classification models. It compares the predicted probability \( p_i \) to the actual label \( y_i \).
Lower log loss values indicate better model performance. A perfect model would have a log loss of 0. Cross-entropy loss is an extension of log loss to multi-class problems.
The cross-entropy loss formula is:
$$L(y, p) = -\sum_{i} y_i \log(p_i)$$
Some key advantages of using cross-entropy loss for classification tasks:
- Easy to implement and optimize in most neural network frameworks.
- The convex shape allows efficient gradient-based optimization to find the global minimum.
- Penalizes overconfident incorrect predictions more than errors where the model is unsure.
- Invariant to shifts/scaling, allowing calibration of predicted probabilities.
- Works well for imbalanced classification problems by focusing on the performance of the positive class.
Monitoring the log loss during training can help identify when overfitting starts to occur.
Bias and Variance
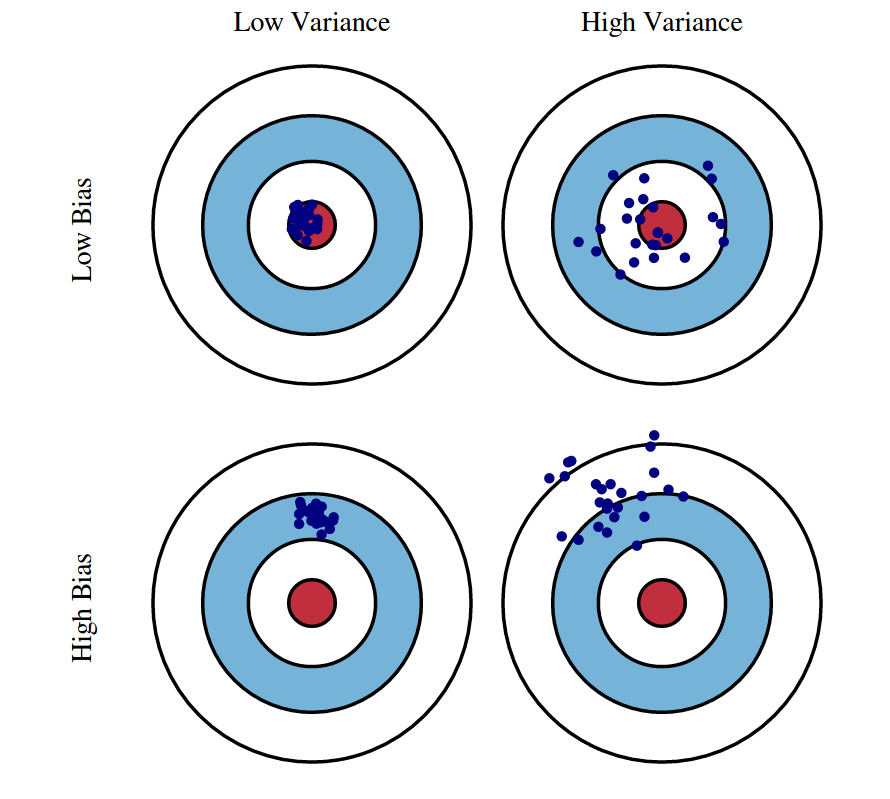
Model performance is impacted by bias and variance trade-offs.
- Bias: Occurs when a model cannot capture the true relationships within the data, often leading to underfitting. High-bias models make strong assumptions about the data's shape that may not align with reality.
- Variance: Relates to a model's sensitivity to fluctuations in the training data, leading to overfitting. High variance models perform exceptionally on training data but poorly on unseen data.
Evaluating bias and variance helps diagnose the underlying issues impacting model accuracy.
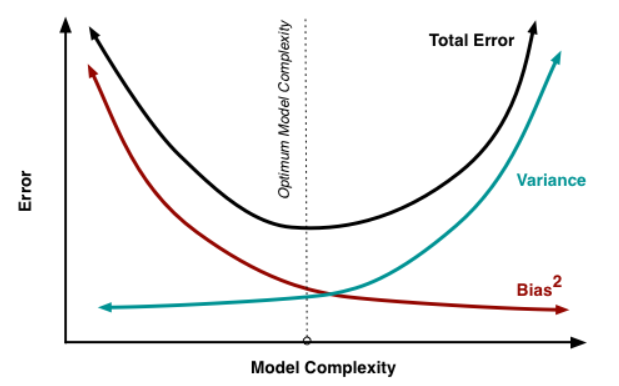
The bias-variance trade-off is key:
- There is a trade-off between minimizing bias and minimizing variance in any model. Typically, as one increases, the other decreases.
- Low bias and low variance are the goals for optimal model performance. However, some trade-offs must always be made between the two.
- For example, simple linear models often have high bias and low variance, while complex non-linear models often have low bias but very high variance.
Implications:
- With high bias, adding model complexity can help improve performance.
- With high variance, constraining models through regularization or reducing complexity can help.
So, evaluating the levels of bias and variance informs the next steps for improving model accuracy. The optimal balance depends on the problem and achieving the lowest total error.
Holdout Method
The holdout method splits data into training and test sets. The test set provides an unbiased evaluation of the final model fit on the training set.
Typical splits are 80/20 or 70/30 training/test. The test set mimics real-world data and allows you to estimate model performance on new data.
K-fold cross-validation is an extension that creates multiple train/test splits and average performance. It helps reduce variance in the estimates.
AUC-ROC Curve
The AUC-ROC is a performance measurement for classification problems at various threshold settings. Here, ROC stands for Receiver Operating Characteristic, and AUC represents the Area Under the Curve.
The ROC curve plots the true positive rate (TPR), also known as sensitivity or recall, against the false positive rate (FPR), also known as the fall-out or probability of false alarm, at different classification thresholds.
The area under this curve (AUC) measures discrimination - the ability to differentiate positive and negative classes. A higher AUC is better, with 1 being perfect classification and 0.5 equal to random guessing.
The AUC-ROC curve is particularly useful for evaluating binary classification models as it provides a comprehensive view of their performance across all classification thresholds.
Precision vs. Recall
Precision (=positive predictive value) and recall (=TPR) provide detailed insight into binary classification models. Precision looks at positive predictions, and recall looks at actual positives.
The precision-recall curve plots precision on the y-axis and recall on the y-axis, illustrating the trade-off between these metrics at various threshold settings.
A model that achieves high precision and recall scores is considered effective, but often, improving precision comes at the expense of recall, and vice versa. This trade-off is visually represented in the curve, where a curve closer to the top-right corner indicates a better-performing model. The area under the precision-recall curve (AUC-PR) is a single metric that summarizes the model’s overall ability to yield high precision and recall across different thresholds, with a higher AUC-PR indicating a superior model performance.
AUC-ROC and Precision vs Recall - When should you use which?
As true-positive rate equals recall, they only differ in what they compare it to - FPR for ROC and precision for PR.
Some key differences and things to note:
- ROC curves are appropriate when the observations are balanced between each class. PR curves are more useful for imbalanced classification datasets as they focus more on the performance of the positive class.
- The baseline in ROC space is fixed - for a random classifier, it is the diagonal line with AUC=0.5. The PR baseline depends on the relative frequency of positives, so AUC values can't be directly compared between datasets.
- The PR curve captures the effect of all confidence thresholds, while the ROC curve only captures those that appear as the discrimination threshold is varied. So, for discrete classifiers, the PR curve may provide more detail.
So, in summary:
- For balanced binary classification, ROC curves are a better choice.
- PR curves highlight the performance differences better for imbalanced binary classification, but ROC still gives an overall picture of discrimination ability.
- For multiclass classification, ROC curves can be created from the one-vs-all approach and summarize performance well; PR curves are more difficult to adapt.
So, depending on the problem, both ROC and precision-recall analysis can provide complementary information about a classifier's performance. When classes are balanced, ROC is typically sufficient on its own.
Advanced Topics in Machine Learning Classification
Machine learning classification has evolved significantly, driven by advancements in deep learning, the need to handle imbalanced datasets, and the continuous development of new algorithms.
This section delves into these advanced topics, exploring how deep learning has transformed classification tasks, the strategies for managing imbalanced datasets, and the future trends that will shape the next generation of classification algorithms.
Deep Learning for Classification: Beyond Traditional Algorithms
Deep learning has significantly advanced the field of machine learning, particularly in classification tasks. Unlike traditional algorithms that rely on manually engineered features, deep learning models can automatically learn hierarchical representations from raw data, making them highly effective for complex classification problems. Key aspects of deep learning for classification include:
- Deep Learning Architectures: Popular architectures such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are widely used for image and sequence classification tasks.
- Transfer Learning: Leveraging pre-trained models on large datasets (e.g., ImageNet) to fine-tune specific tasks, which can save time and computational resources while improving performance.
- Handling Large-Scale Data: Deep learning models excel at processing large-scale and high-dimensional data, making them suitable for tasks like image recognition, natural language processing, and more.
- Practical Applications: Deep learning is used in various applications, including image classification, sentiment analysis, language translation, and more.
Handling Imbalanced Datasets in Classification
Imbalanced datasets are common in real-world classification problems, where one class is significantly underrepresented compared to others. This imbalance can lead to biased models that perform poorly in the minority class. Techniques to handle imbalanced datasets include:
- Under-sampling: Reducing the number of majority class samples to balance the dataset, though this can lead to loss of valuable information.
- Oversampling: Increasing the number of minority class samples by duplicating them or using techniques like SMOTE (Synthetic Minority Over-sampling Technique) to generate synthetic samples.
- Ensemble Methods: Combining multiple models trained on balanced subsets of the data to improve overall performance.
- Adjusting Class Weights: Modifying the loss function to penalize misclassifications of the minority class more heavily makes the model more sensitive to this group.
- Evaluation Metrics: Using metrics like precision, recall, F1-score, and AUC-ROC provides a more comprehensive evaluation of model performance on imbalanced datasets.
The Future of Classification Algorithms in Machine Learning
Machine learning is rapidly evolving, with new advancements in classification algorithms continually emerging. Future trends and potential developments in classification algorithms include:
- Few-Shot Learning: Techniques enabling models to learn from a few examples make them more efficient and adaptable to new tasks with limited data.
- Meta-Learning: Also known as "learning to learn," this technique involves training models to adapt quickly to new tasks by leveraging prior knowledge.
- Explainable AI: Developing models that provide interpretable and transparent predictions, which is crucial for applications in healthcare, finance, and other critical domains.
- Ethical Considerations: Addressing biases in data and models, ensuring fairness, and developing guidelines for the responsible use of AI in classification tasks.
Tools and Resources for Machine Learning Classification
This section contains an overview of essential tools and resources for machine learning classification. It covers Python libraries, online courses and tutorials, and datasets.
Python Libraries for Machine Learning Classification
Python is a popular language for machine learning, offering a variety of powerful libraries that simplify the implementation of classification algorithms. Some of the most widely used Python libraries for machine learning classification include:
- Scikit-learn: A comprehensive library that provides simple and efficient data mining and analysis tools. It includes various classification algorithms such as logistic regression, decision trees, support vector machines (SVMs), and ensemble methods like random forests and gradient boosting.
- TensorFlow: An open-source library developed by Google, TensorFlow is widely used for building and training deep learning models. It supports various neural network architectures for classification tasks, including Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs).
- PyTorch: Developed by Facebook's AI Research lab, PyTorch is another popular deep learning library that provides flexibility and ease of use. It is particularly favored for research and development of deep learning models due to its dynamic computational graph and extensive support for GPU acceleration.
- Keras: A high-level neural networks API, Keras is built on top of TensorFlow and provides a user-friendly interface for building and training deep learning models. It is known for its simplicity and ease of use, making it accessible for beginners and efficient for rapid prototyping.
- XGBoost: An optimized gradient boosting library designed for speed and performance. XGBoost is widely used in machine learning competitions and real-world applications for its efficiency and accuracy in handling large-scale datasets and complex classification tasks.
These libraries offer extensive documentation, tutorials, and community support, making them accessible for beginners and experienced practitioners.
Online Courses and Tutorials to Get You Started
Learning machine learning classification can be daunting, but numerous online courses and tutorials are available to help you get started. Some recommended resources include:
- Coursera - Machine Learning by Andrew Ng: This course, offered by Stanford University, is one of the most popular and comprehensive introductions to machine learning. It covers various classification algorithms and practical applications.
- Udacity - Intro to Machine Learning with PyTorch and TensorFlow: This course focuses on the practical implementation of machine learning algorithms using popular libraries like PyTorch and TensorFlow.
- Kaggle - Learn Machine Learning: Kaggle offers a series of tutorials and hands-on exercises to help you learn machine learning classification techniques and apply them to real-world datasets. Below are a few Kaggle Notebooks that will help you get started:
Datasets for Practicing Classification Techniques
Access to high-quality datasets is crucial for practicing and evaluating classification models. Some popular sites from where you can get datasets for machine learning classification include:
- Kaggle
- Hugging Face
- UCI Machine Learning Repository
- Open ML
- DagsHub
- Google Dataset Search
- AWS Public Dataset
Conclusion
In Part 2 of the series on machine learning classification, we discussed advanced topics, providing a deeper understanding of how deep learning is revolutionizing classification tasks and offering strategies to handle imbalanced datasets. We also looked ahead to the future of classification algorithms, highlighting emerging trends and innovations.
We then focused on the critical aspect of model evaluation, discussing various metrics and methods to ensure your classification models are accurate and reliable. Understanding these evaluation techniques is essential for developing robust models that perform well in real-world scenarios.
Lastly, we provided a comprehensive overview of the tools and resources available for machine learning classification. These resources, from powerful Python libraries to online courses and datasets, are designed to help you effectively implement and practice classification techniques.
By integrating these advanced topics, evaluation methods, and practical tools into your workflow, you will be well-equipped to tackle complex classification problems and stay ahead in the rapidly evolving field of machine learning. If you enjoyed this series, subscribe to the blog for more insightful content and updates.

Stay Informed, Stay Inspired.
Join the newsletter to receive the latest updates in your inbox.
🚫 No spam. Unsubscribe anytime .


){kind=link}